https://itinai.com/aws-launches-swe-polybench-a-comprehensive-open-source-benchmark-for-ai-coding-agents/
AWS Introduces SWE-PolyBench: A New Open-Source Multilingual Benchmark for Evaluating AI Coding Agents
Introduction
Recent advancements in large language models (LLMs) have led to the creation of AI coding agents capable of generating, modifying, and understanding software code. However, evaluating these systems has been challenging, as existing benchmarks often focus narrowly on synthetic tasks, primarily in Python. This limitation means that many agents may not demonstrate the robust capabilities needed for real-world applications.
SWE-PolyBench: A Comprehensive Evaluation Framework
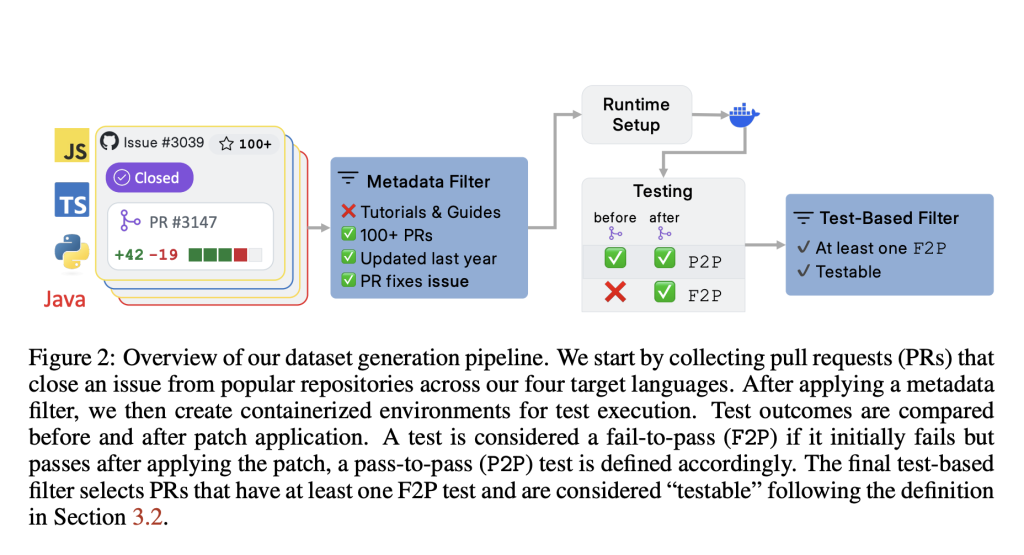
To overcome these challenges, AWS AI Labs has launched SWE-PolyBench, a multilingual benchmark designed for the execution-based evaluation of AI coding agents. This benchmark encompasses 21 GitHub repositories across four popular programming languages: Java, JavaScript, TypeScript, and Python. It includes 2,110 tasks such as bug fixes, feature implementations, and code refactorings.
Key Features of SWE-PolyBench
- Real Pull Requests: Unlike previous benchmarks, SWE-PolyBench utilizes actual pull requests that resolve real issues, complete with associated test cases for verifiable evaluation.
- SWE-PolyBench500: A smaller, stratified subset designed for quicker experimentation while maintaining task and language diversity.
Technical Structure and Evaluation Metrics
SWE-PolyBench employs an execution-based evaluation pipeline. Each task includes a repository snapshot and a problem statement derived from a GitHub issue. The evaluation process applies the corresponding ground truth patch in a containerized test environment tailored for the specific programming language. Outcomes are measured using two types of unit tests: fail-to-pass (F2P) and pass-to-pass (P2P).
Concrete Syntax Tree (CST) Metrics
To enhance the assessment of coding agents, SWE-PolyBench introduces CST-based metrics. These metrics evaluate the agent’s ability to locate and modify relevant sections of the codebase, providing insights beyond simple pass/fail outcomes, especially for complex modifications involving multiple files.
Empirical Evaluation and Observations
Three open-source coding agents—Aider, SWE-Agent, and Agentless—were adapted for SWE-PolyBench, utilizing Anthropic’s Claude 3.5 model. The evaluation highlighted significant performance variations across programming languages and task types. For example, agents achieved a pass rate of up to 24.1% on Python tasks but only 4.7% on TypeScript tasks.
Performance Insights
- Task Complexity: Simpler tasks, such as single-function changes, yielded higher success rates (up to 40%), while more complex, multi-file changes saw a notable decline in performance.
- Localization Challenges: High retrieval precision for file and CST node identification did not always correlate with higher pass rates, indicating that while code localization is essential, it is not sufficient for successful problem resolution.
Conclusion: Towards Robust Evaluation of AI Coding Agents
SWE-PolyBench offers a comprehensive evaluation framework that addresses critical limitations in existing benchmarks. By supporting multiple programming languages and incorporating syntax-aware metrics, it provides a more accurate assessment of an agent’s real-world applicability. The findings indicate that while AI agents show potential, their performance can be inconsistent across different languages and tasks. SWE-PolyBench lays the groundwork for future research aimed at enhancing the generalizability and reasoning capabilities of AI coding assistants.
Call to Action
Explore how artificial intelligence can transform your business processes. Identify areas where AI can add value, set key performance indicators (KPIs) to measure impact, and select tools that align with your objectives. Start with small projects to gather data and gradually expand your AI initiatives.
If you need assistance in managing AI in your business, please contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.
https://itinai.com/aws-launches-swe-polybench-a-comprehensive-open-source-benchmark-for-ai-coding-agents/
#AWS #AICodingAgents #OpenSource #SoftwareDevelopment #Benchmarking
No comments:
Post a Comment