https://itinai.com/symbolic-moe-adaptive-mixture-of-experts-framework-for-pre-trained-llms/
Understanding Large Language Models (LLMs)
Large language models (LLMs) possess varying skills and strengths based on their design and training. However, they often struggle to integrate specialized knowledge across different fields, which limits their problem-solving abilities compared to humans. For instance, models like MetaMath and WizardMath excel in mathematical reasoning but may lack common sense or medical knowledge. This highlights the need for frameworks that can effectively identify and select the right expert models for specific challenges.
Current Approaches to Model Specialization
Existing methods, such as Mixture-of-Experts (MoE) models, distribute tasks among multiple specialized components. Recent advancements focus on sparse approaches that activate only the most relevant experts for each input. The Sparse MoE (SMoE) method has enhanced efficiency across various tasks but requires complex model integration through joint training. Newer frameworks like Mixture-of-Agents (MoA) aim to combine LLM outputs symbolically, while multi-agent reasoning techniques, such as the Student-teacher method, allow for collaborative argument refinement.
Introducing SYMBOLIC-MOE
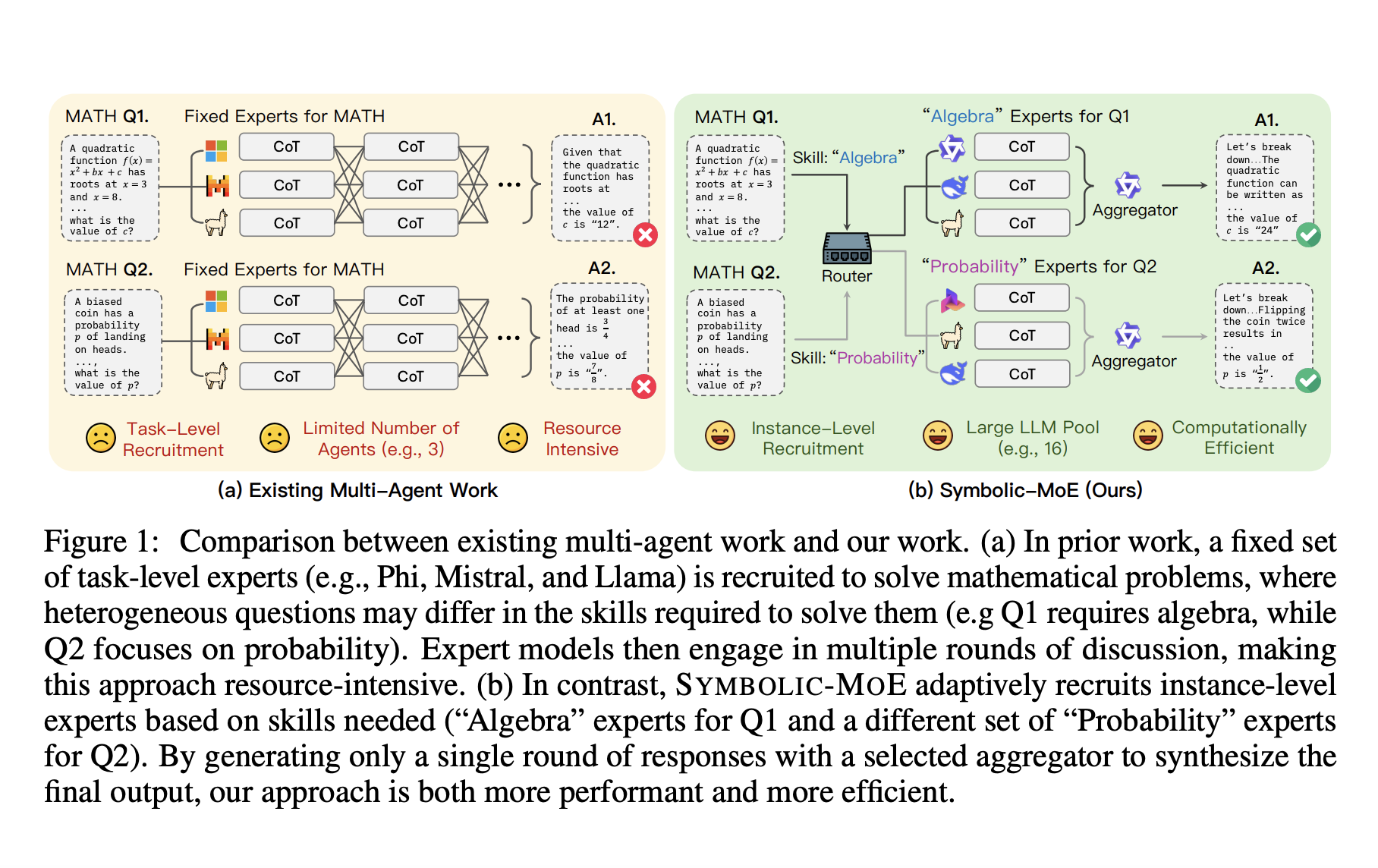
Researchers from UNC Chapel Hill have developed SYMBOLIC-MOE, a symbolic and text-based Mixture-of-Experts framework that enables adaptive mixing of pre-trained LLM experts. This framework focuses on specialized skills within broader domains, such as algebra in mathematics or molecular biology in biomedical reasoning. It employs a skill-based recruiting strategy to dynamically select the most relevant expert LLMs for each reasoning task, demonstrating an average improvement of 8.15% over leading multi-agent approaches.
How SYMBOLIC-MOE Works
SYMBOLIC-MOE operates in three stages: creating model profiles, selecting aggregators, and recruiting experts for answer generation during inference. To enhance efficiency, it uses an innovative batching strategy that analyzes all instances to determine necessary LLMs. This allows for intelligent grouping of problem instances, ensuring that each expert model processes relevant instances in a single batch, optimizing throughput on a single GPU while accommodating a diverse pool of 16 LLMs.
Performance and Efficiency
SYMBOLIC-MOE consistently outperforms existing models across various benchmarks, achieving significant improvements over single-model strategies and multi-agent frameworks. It demonstrates comparable performance to larger models while operating 44% faster on a single GPU than MoA, all while maintaining better accuracy.
Conclusion
SYMBOLIC-MOE represents a scalable MoE framework that effectively combines models through their symbolic outputs. It identifies required skills for specific problems and recruits agents accordingly, leading to superior performance across diverse domains without human intervention. While it offers significant advantages, it also has limitations, such as increased inference costs due to multiple model runs and reliance on a small validation set for agent profiling.
Next Steps
Explore how artificial intelligence can enhance your business processes. Identify areas for automation, assess key performance indicators (KPIs) to measure AI impact, and select tools that align with your objectives. Start with small projects to gather data and gradually expand your AI initiatives.
If you need assistance in managing AI in your business, contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.
https://itinai.com/symbolic-moe-adaptive-mixture-of-experts-framework-for-pre-trained-llms/
#LargeLanguageModels #MachineLearning #ArtificialIntelligence #ModelSpecialization #SYMBOLICMOE
No comments:
Post a Comment